
Finn의 개발블로그
엘라스틱서치(Elasticsearch) 사용하기(1) 본문

1. Elastic Search란?
- 아파치 루씬을 기반으로 개발된 오픈소스 분산 검색 엔진(서버)
2. Elastic Search 특징?
- 루씬을 기반으로 만들어져 루씬의 기능을 대부분 지원
- 사용자 위치 정보 이용가능
- 다국어 검색 지원
- 자동 완성 지원
- 미리 보기 지원
- 철자 수정 기능 지원
- 분산 시스템
- 엘라스틱 서치는 여러개의 노드로 구성되는 분산 시스템
- 노드는 데이터를 색인하고 검색을 수행하는 단위 프로세스
- 기존 노드에 새 노드를 실행하여 연결하는 것만으로 확장 가능
- 데이터는 각 노드에 분산 저장
- 복사본을 유지하여 각종 출동로부터 노드 데이터 보호
- DISCOVERY를 내장하여 별도의 분산 시스템 관리자 불필요
- 높은 가용성
- 엘라스틱 서치는 하나 이상의 노드로 구성
- 각 노드는 1개 이상의 데이터 우너본과 복사본을 서로 다른 위치에 나누어 저장
- 노드가 종료되거나 실행에 실패할 경우 다른 노드로 데이터 이동
- 위의 특징으로 인해 높은 가용성과 안정성 보장
- 멀티 테넌시
- 데이터는 여러 개로 분리된 인덱스들의 그룹으로 저장
- 서로 다른 인덱스의 데이터를 하나의 질의로 검색하여 하나의 출력으로 도출 가능
- JSON DOCUMENT
- 기본적으로 모든 필드를 색인 후 JSON 구조로 저장
- JSON 구조로 인해 모든 레ㅔㅂㄹ의 필드에 접근이 쉽고, 빠른 속도로 검색 가능
- 사전 매핑 없이 JSON 문서 형식으로 데이터를 입력하면 바로 색인 작업 수행
- RESTFUL API
- REST 자원은 색인된 데이터 및 질의, 검색되어 JSON형식으로 출력된 문서를 의미
- JSON 문서를 URI로 명시, 이 문서를 처리 하기 위해 HTTP METHOD 이용
- 실시간 분석
- 저장된 데이터는 검색에 사용되기 위해 별도의 재시작 / 갱신이 불필요
- 색인 작업이 완료됨과 동시에 바로 검색 가능
- 실시간 분석 / 검색은 데이터 증가량에 구애 받지 않음
3. Elastic Search 구조
- 클러스터
- 클러스터는 엘라스틱서치의 가장 큰 시스템 단위
- 하나의 클러스터는 여러 개의 노드로 이루어짐
- 같은 클러스터의 이름으로 노드를 실행하는 것만으로 자동 확장
- 노드
- 노드는 마스터 노드와 데이터 노드로 구분
- 마스터 노드는 전체 클러스터 상태의 메타 정보를 관리
- 기존의 마스터 노드가 종료되는 경우 새로운 마스터 노드가 선출됌
- 데이터 노드는 실제 데이터가 저장되는 노드
- 샤드와 복사본
- 샤드는 데이터 검색을 위해 구분되는 최소 단위
- 색인된 데이터는 여러 개의 샤드로 분할돼 저장
- 기본적으로 인덱스당 5개의 샤드와 5개의 복사본으로 분리
- 데이터가 색인돼 저장되는 공간을 Primary Shard라 함
- 최초 샤드에 데이터가 색인되면 동일한 수 만큼 복사본을 생성
4. Elastic Search Data 구조
- Index
- 비슷한 특성을 가진 문서의 모음
- index은 이름(모두 소문자)으로 식별
- 이름은 색인에 포함된 문서에 대한 색인화, 검색, 업데이트, 삭제 작업에서 해당 색인을 가리키는 데 사용
- Type
- index에서 하나 이상의 타입을 정의
- index을 논리적으로 분류/구분한 것이며 그 의미 체계는 전적으로 사용자가 결정
- Document
- 색인화할 수 있는 기본 정보 단위
- JSON 형식
- Field
- 엘라스틱서치 문서는 JSON이다. JSON의 각 프로퍼티를 엘라스틱서치에서 필드
- Mapping
- 인덱스/타입/문서의 규칙을 정의
RDBMS와 데이터 구조 비교
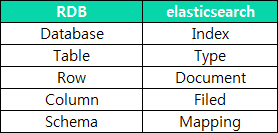
참조 - https://www.slideshare.net/seunghyuneom/elastic-search-52724188